Los Sistemas de computación empotrados debe cumplir con los costos ajustados, el consumo de energía, y las limitaciones de rendimiento. Si uno de los requisitos de diseño dominado, la vida sería mucho más fácil para los diseñadores de sistemas embebidos, que podrían utilizar arquitecturas estándares con los modelos de programación fácil.
Pero debido a que las tres restricciones se deben cumplir al mismo tiempo, los diseñadores de sistemas embebidos, tienen que moldear arquitecturas de hardware y software para adaptarlo a las necesidades de las aplicaciones. El Hardware especializado ayuda a cumplir con los requisitos de rendimiento, para un menor consumo energético y menor costo de lo que sería posible, en un sistema de propósito general.
Como hemos visto, los sistemas informáticos incorporados a menudo son multiprocesadores heterogéneos con múltiples CPUs, y los elementos de cableado de procesamiento (PE). En co-diseño, el cableado PEs, son generalmente conocidas como aceleradores. En contraste, un co-procesador es controlado por la unidad de ejecución de una CPU.
Hardware / software de co-diseño, es un conjunto de técnicas que los diseñadores utilizan para ayudarles, a crear eficientes sistemas de aplicaciones específicas.
Si usted no sabe nada acerca de las características de la aplicación, entonces es difícil saber cómo ajustar el diseño del sistema. Pero si usted sabe de la aplicación, como el diseñador, no sólo se puede agregar características a la de hardware y software, que hacen correr más rápido usando menos energía.
Pero también puede eliminar los elementos de hardware y software, que no ayudan con la aplicación en cuestión. La Eliminación de componentes en exceso suele ser tan importantes, como la adición de nuevas características.
Como su nombre indica, hardware / software de co-diseño, de los medios en forma conjunta el diseño de arquitecturas de hardware y software para cumplir con el rendimiento, costos y objetivos de la energía. El Co-diseño, es una metodología radicalmente diferente a las abstracciones de capas utilizadas en la computación de propósito general.
Debido a que el co-diseño, intenta optimizar distintas partes del sistema, al mismo tiempo, se hace un uso extensivo de herramientas de análisis de diseño y optimización.
Cada vez más, hardware / software de co-diseño, está siendo utilizados para el diseño de sistemas empotrados en si. Por ejemplo, los servidores, se pueden mejorar con implementaciones especializadas de algunas de las funciones de su pila de software. El Co-diseño se puede aplicar a alojamiento web con la misma facilidad, ya que puede ser aplicada a multimedia.
En esta serie, en primer lugar se llevará una breve mirada a algunas plataformas de hardware, que pueden ser utilizados como objetivos de hardware / software de co-diseño, seguido de un examen de análisis de rendimiento, difícil de hardware / software de co-síntesis y, por último, cosimulación del hardware / software.
Plataformas de diseño
El Hardware / software de co-diseño, puede ser utilizado para diseñar sistemas desde cero o crear sistemas, para ser implementados en una plataforma existente. La arquitectura de CPU + acelerador, es un común al co-diseño de la plataforma. Una variedad de diferentes CPUs, se pueden utilizar para albergar el acelerador.
El acelerador puede implementar muchas funciones diferentes, y además, utilizando cualquier de las tecnologías de la lógica de varios. Estas decisiones influyen en el tiempo de diseño, el consumo de energía, y otras características importantes del sistema.
La plataforma de co-diseño, puede ser implementado en cualquiera de las diversas tecnologías de diseño muy diferente.
1) Un sistema basado en PC, con el acelerador situado en un tablero conectado en el bus del PC. El Plug-in, puede utilizar un chip o un Field Programmable Gate Array (FPGA), para implementar el acelerador. Este tipo de sistema es relativamente voluminoso, y es la más utilizada para el desarrollo de aplicaciones o muy bajo volumen.
2) Una placa de circuito impreso personalizado, utilizando una FPGA o un circuito integrado de encargo para el acelerador. El consejo personalizado requiere más trabajo de diseño de un sistema basado en PC, pero los resultados en un menor costo, bajo consumo de energía del sistema.
3) Una plataforma FPGA que incluye una CPU y una tela de FPGA en un solo chip. Estos chips son más caros que los chips, sino proporcionar una implementación de un solo chip con uno o más CPUs, y una gran cantidad de lógica personalizada.
4) Un circuito integrado de encargo, por lo que el acelerador implementa una función en un área menor y con menor consumo de energía. Muchos sistemas integrados en chips (SoC), hacer uso de aceleradores para determinadas funciones.
La combinación de una CPU más aceleradores de uno o más es la forma más simple de plataformas heterogéneas, hardware / software de partición de los objetivos de dichas plataformas. La CPU se conoce como el anfitrión. Las conversaciones de la CPU, en el acelerador a través de los datos y registros de control en ella. Estos registros permiten a la CPU, para controlar el funcionamiento del acelerador y darle órdenes.
La CPU y el acelerador, también puede comunicarse a través de memoria compartida. Si el acelerador necesita para operar en un gran volumen de datos, por lo general es más eficiente dejar los datos en la memoria, que el acelerador de lectura y escritura de memoria directamente, en lugar de tener los datos de transporte de la CPU, de la memoria a los registros de aceleración y la espalda.La CPU, y el acelerador de sincronizar sus acciones.
Las Plataformas más generales también son posibles. Podemos utilizar varias CPU, en contraste con el procesador conectado a los aceleradores. Podemos generalizar el sistema de interconexión de un autobús a las estructuras más generales.
Además, podemos crear un sistema de memoria más complejo que ofrece diferentes tipos de acceso a diferentes partes del sistema. El Co-diseño de estos tipos de sistemas es más difícil, sobre todo cuando no hacemos suposiciones sobre la estructura de la plataforma.
Los Tres ejemplos siguientes, se describen varios de los diseños diferentes de las co-plataformas que utilizan FPGAs, de diferentes maneras.
Ejemplo 7-1.
El Xiilnx Virtex-4 FX Plataforma FPGA Familia

El Xilinx Virtex-4 de la familia [Xi105], es una plataforma FPGA que viene en diferentes configuraciones. La familia de alta gama FX incluye uno o dos procesadores PowerPC, múltiples MACS Ethernet, memoria RAM de bloque, y grandes conjuntos de lógica reconfigurable.

El PowerPC, es de alto rendimiento con 32-bit RISC Machine, dispone de una gama de cinco etapas, 32 registros de propósito general, y la instrucción por separado y los cachés de datos. La tela de FPGA, se basa en bloques de lógica configurables (CLB) que utilizan las tablas de búsqueda y una variedad de otra lógica.
El más grande Virtex-4 proporciona hasta 200.000 células de la lógica. El CLB, se pueden utilizar para implementar sumadores de alta velocidad. Un conjunto separado de los bloques incluye 18 x 18 multiplicadores, sumadores uno, y un acumulador de 48 bits, para las operaciones de DSP. El chip incluye una serie de bloques de memoria RAM que se puede configurar para una variedad de configuraciones de profundidad y anchura.
El PowerPC, y el tejido FPGA puede ser perfectamente integrado. La tela de FPGA, se pueden utilizar para construir basado en bus. Una unidad de procesador auxiliar permite costumbre instrucciones PowerPC a implementar en el tejido FPGA.
Además, los núcleos del procesador también puede ser aplicado en el tejido FPGA, para construir multiprocesadores heterogéneos. Xilinx proporciona el núcleo del procesador MicroBlaze y otros núcleos se puede utilizar también.
El MicroBlaze es un procesador soft core diseñados para Xilinx FPGA de Xilinx .Como un procesador soft-core, MicroBlaze se lleva a cabo en su totalidad en la memoria de uso general y el tejido de la lógica FPGA de Xilinx.
Ejemplo 7-2.
El integrador de ARM módulo lógico

El integrador de ARM, es una serie de placas de evaluación para el procesador ARM. El módulo lógico Integrador [ARM00], es una tarjeta aceleradora de FPGA, que se conecta a la placa base Integrador de ARM.
El módulo lógico proporciona una FPGA Xilinx, para la lógica reconfigurable. Las interfaces FPGA con el bus ARM AMBA. La placa del módulo de la lógica no contiene la SRAM, la propia FPGA puede usar el bus AMBA para conectarse a la SRAM y los dispositivos de E / S que figuran en otros foros.
Ejemplo 7-3.
La Annapolis Micro Systems Wildstar II Pro

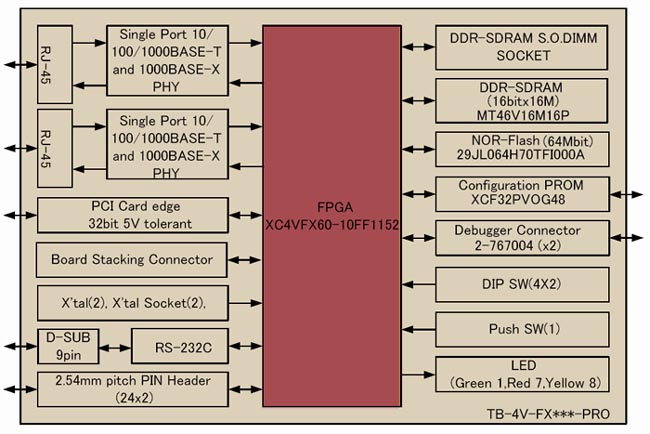
El Wildstar II Pro (http://Www.annapmicro.com), es una tarjeta de bus PCI que proporciona la lógica FPGA, en el bus de un PC o un dispositivo PCI. La tarjeta recibe uno o dos FPGAs Virtex II, Pro que pueden conectarse directamente al bus PCI.
También tiene capacidad para 96 MB de SRAM y 256 MB de SDRAM. La tarjeta está organizado como se muestra en la figura. Un entorno de desarrollo simplifica el diseño del sistema de la junta.
Análisis de rendimiento
Durante la co-síntesis, tenemos que evaluar como el hardware están diseñando. El Alto nivel de síntesis ha sido desarrollado para aumentar el nivel de abstracción, para los diseñadores de hardware, pero también es útil como una herramienta de estimación de co-síntesis.
En esta sección se examinan algunos algoritmos de síntesis de alto nivel, para proporcionar una mejor comprensión de los costos de hardware y algoritmos rápidos de la zona y la estimación del rendimiento.También tenemos en cuenta las técnicas desarrolladas específicamente para estimar los costos, de los aceleradores en multiprocesadores heterogéneos.
Alto nivel de la síntesis.
El Alto nivel de síntesis, se inicia a partir de una descripción del comportamiento de hardware, y crea un diseño de trasferencia entre registros. El Alto nivel de la síntesis de los horarios y asignar las operaciones en el comportamiento, así como los mapas de las operaciones en las bibliotecas de componentes.

Figura 1.7 Un ejemplo de especificación de la conducta y la aplicación de trasferencia entre registros.
Figura 7-1 arriba muestra un ejemplo sencillo de una especificación de alto nivel y una posible implementación de trasferencia entre registros. Los bordes de la dependencia de los datos transportan valores de las variables de una operación o de las entradas principales a otro.
La transferencia de registros, la ejecución de los pasos que deben tomarse a su vez, la especificación de alto nivel, si se administra en forma de texto o un gráfico de flujo de datos, en una aplicación de registro de la transferencia:
Las operaciones se han programado para ocurrir en un ciclo de reloj en particular. Las Variables han sido asignadas a los registros. Las operaciones se han asignado a las unidades de función. Algunas conexiones se han multiplexado para salvar a los cables.
En este caso, se ha supuesto que se puede ejecutar una sola operación por ciclo de reloj. Un ciclo de reloj a menudo se llama una medida de control o de paso de tiempo en la síntesis de alto nivel.
Utilizamos un modelo más grueso de tiempo de alto nivel de síntesis, que se utiliza en la síntesis de la lógica. Debido a que estamos más lejos de la ejecución, las demoras no se puede predecir con la mayor precisión, modelos de tiempos tan detallados no son de mucha utilidad, en el alto nivel de síntesis. La Abstracción de tiempo para el período de reloj o una fracción, de lo que hace la combinatoria de programación tratable.
La asignación de variables a los registros deben hacerse con cuidado. Dos variables pueden compartir un registro si sus valores no son necesarios en el momento, para el mismo ejemplo, si un valor de entrada se utiliza únicamente al principio de una secuencia de cálculos y se define otra variable sólo al final de la secuencia.
Pero si las dos variables se necesitan al mismo tiempo, que deben asignarse a registros distintos. Compartir o registros o unidades funcionales requiere la adición de multiplexores en el diseño.
Por ejemplo, si dos adiciones en el gráfico de flujo de datos se asignan a la unidad de víbora, en la misma ejecución, se utiliza para alimentar a los multiplexores con operandos propios de la víbora.
Los multiplexores son controlados por un control FSM, que suministra las señales de seleccionar a los muxes. (En la mayoría de los casos, no necesitamos de-multiplexores en las salidas de las unidades compartidas, ya que el hardware, es generalmente diseñado para ignorar los valores, que no se utilizan en cualquier ciclo de reloj.) Debemos añadir multiplexores de tres tipos de costos, de la aplicación:
1. Delay, que puede prolongarse el ciclo de reloj del sistema.
2. Logic, que consume la zona en el chip.
3 .Cableado, lo que se requiere para alcanzar el multiplexor, también se requiere un área.
El Compartir hardware no es siempre una victoria. Por ejemplo, en algunas tecnologías, las víboras son lo suficientemente pequeñas que se gana tanto en el área y la demora por no compartir una víbora. Parte de la información necesaria para tomar buenas decisiones de aplicación debe provenir de una biblioteca de la tecnología, lo que da a la zona y los costos de demora de algunos componentes.
Otros datos, como las estimaciones de costos de cableado, se puede hacer mediante algoritmos. La capacidad de un programa para medir con precisión los costos de implementación de un gran número de implementaciones candidato, es uno de los puntos fuertes de los algoritmos de síntesis de alto nivel.
Durante la búsqueda de un buen horario, el que-pronto-como-posible (ASAP) ,y como a fines de los posible (ALAP), cuáles son los límites de la longitud útil programa.
Una heurística muy simple que puede manejar las limitaciones es el primero que llega-firstserved (FCFS), de programación. FCFS camina a través de la gráfica de flujo de datos desde sus fuentes hasta sus sumideros.
Tan pronto como encuentra un nuevo nodo, se trata de programar la operación en el horario actual del reloj, y si todos los recursos están ocupados, se inicia otro paso de control de horarios y la operación allí.
Los Horarios FCFS, generalmente manejan los nodos de la fuente al sumidero, pero los nodos que aparecen en la misma profundidad en el gráfico, se pueden programar en un orden arbitrario. La calidad de la programación, según lo medido por su longitud, puede variar enormemente dependiendo exactamente de qué orden de los nodos a una determinada profundidad se consideran.
FCFS, ya que elige a los nodos de profundidad igual forma arbitraria, puede retrasar una operación crítica. Una mejora evidente es un algoritmo de planificación de la ruta crítica, que las operaciones de los horarios en la ruta crítica en primer lugar.
La programación de la lista, es una heurística eficaz que trata de mejorar en la programación de la ruta crítica, mediante una consideración más equilibrada de fuera de la crítica de la ruta los nodos.
En lugar de tratar a todos los nodos que están fuera de la ruta crítica como igualmente importantes, la programación de la lista estima que tan cerca de un nodo es ser crítico, mediante la medición de D, el número de los descendientes del nodo, en el gráfico de flujo de datos. Un nodo con los descendientes de unos pocos es menos probable que se convierta importante, que otro nodo a la misma profundidad que tiene más descendientes.
La programación de la lista también atraviesa el gráfico de flujo de datos desde las fuentes a los sumideros, pero cuando se tiene varios nodos a la misma profundidad que compiten por la atención, que siempre elige el nodo con la mayoría de los descendientes.
En nuestro modelo de tiempo simple, donde todos los nodos de la misma cantidad de tiempo, un nodo crítico siempre tendrá más descendientes que cualquier nodo crítico. La heurística toma su nombre de la lista de nodos en la actualidad a la espera de ser programadas.
La fuerza dirigida por la programación de [Pau89], es un algoritmo de programación bien conocido que trata de minimizar el costo del hardware, para cumplir con una meta de desempeño particular por equilibrar el uso de unidades funcionales a través de los ciclos. El algoritmo selecciona una operación de programación con las fuerzas (ver la Figura 7-2 a continuación ).
Se asigna entonces una medida de control para la operación. Una vez que la operación ha sido programada, no se mueve, por lo que bucle exterior del algoritmo, se ejecuta una vez para cada operación en el gráfico de flujo de datos.

Figura 7.2.
Cómo las fuerzas de la programación de guía del operador
Para calcular las fuerzas ejercidas sobre los operadores, primero tenemos que encontrar la distribución de las diversas operaciones en el gráfico de flujo de datos, como se representa en un gráfico de distribución.
La ASAP y horarios ALAP, nos dice que la serie de medidas de control en el que puede ser cada operación programada. Suponemos que cada operación tiene una probabilidad uniforme de ser asignada a cualquier medida de control posible.
Un gráfico muestra la distribución del valor esperado, del número de operadores de un determinado tipo de ser asignado a cada paso de control, como se muestra en la Figura 7-3 a continuación.
El gráfico de distribución nos da una visión probabilística del número de unidades de la función de un determinado tipo (víbora en este caso), que serán necesarios en cada etapa de control. En este ejemplo, hay tres incorporaciones, pero no todo puede ocurrir en el mismo ciclo.

Figura 7.3.Ejemplo gráfico de distribución de la fuerza dirigida por la programación
Si calculamos la ASAP y horarios de ALAP, nos encontramos con que + 1 debe ocurrir en el paso de control en primer lugar, + 3 en el pasado, y + 2 Además puede ocurrir en cualquiera de las medidas de control de las dos primeras.
La distribución gráfica de la Dirección General + (t) muestra el número esperado de las adiciones en función de la etapa de control, el valor esperado en cada etapa de control se calcula suponiendo que cada operación es igualmente probable en cada paso de control legal.
Construimos una distribución para cada tipo de unidad de la función que le asignen. El número total de unidades funcionales requeridas para la ruta de datos es la cantidad máxima necesaria para cualquier medida de control. Así que, por lo que minimiza los requisitos de hardware requiere la elección de un programa que equilibra la necesidad de una unidad determinada función a lo largo toda la programación.
Los gráficos de distribución se actualizan cada vez que se programa, cuando una operación de una operación se le asigna a un paso de control, la probabilidad de que la medida de control se convierte en 1 y 0 en cualquier etapa de control.
A medida que la forma de la gráfica de distribución de una función cambia la unidad, la fuerza dirigida por la programación trata de seleccionar las medidas de control para el resto de las operaciones, lo que mantiene la distribución equilibrada del operador.
La fuerza dirigida por la programación calcula fuerzas, como las ejercidas por resortes para ayudar a equilibrar la utilización de los operadores. Las fuerzas de la primavera son una función lineal de desplazamiento, dada por la Ley de Hooke:
F (x) = kx, (EQ 01/07)
donde x es el desplazamiento y la k es la constante del resorte, lo que representa la rigidez del resorte.
Cuando las fuerzas de la informática, en el operador que estamos tratando de programar, lo primero al elegir un horario candidato para el operador, a continuación, calcular las fuerzas de evaluar los efectos de que la elección de la programación de la asignación.
Hay dos tipos de fuerzas aplicadas por los operadores y: las fuerzas de uno mismo y predecesor / sucesor de fuerzas. Las fuerzas de auto están diseñados para igualar la utilización de las unidades de función a través de todas las medidas de control.
Ya que estamos seleccionando un calendario para una operación a la vez, tenemos que tener en cuenta la forma en que la fijación de la operación en el tiempo afectará a otras operaciones, ya sea tirando de las operaciones forward antes o haciendo retroceder los siguientes.
Cuando se elige un candidato a la vez que el operador está previsto, se aplican restricciones a los rangos factibles, de sus inmediatos predecesores y sucesores. (De hecho, los efectos de una opción de programación pueden recorrer toda la gráfica de flujo de datos entera, pero esta aproximación ignora los efectos a distancia.)
El predecesor / sucesor de fuerzas, P o (t) y X(T), son las impuestas a las operaciones predecesor / sucesor. La elección de la programación se evalúa sobre la base de las fuerzas totales en el sistema que ejerce esta opción de programación: las fuerzas de auto, las fuerzas antecesor y el sucesor de las fuerzas de todos se suman.
Es decir, los operadores predecesor y sucesor no directamente ejercen fuerzas sobre el operador de estar programado, pero las fuerzas ejercidas sobre ellos por que la elección de la programación de ayudar a determinar la calidad de la asignación.
En cada paso, se elige la operación con la menor fuerza total de horario y lugar que en la etapa de control en el que se siente la menor fuerza total.
El Camino de la planificación basada en [Cam91], es otro algoritmo de programación conocido por alto nivel de síntesis. A diferencia de los métodos anteriores, la programación basada en rutas está diseñada para minimizar el número de estados de control necesarios en el controlador de la aplicación, las limitaciones en los recursos dada la ruta de datos.
Los horarios de cada algoritmo de ruta de forma independiente, utilizando un algoritmo que garantiza el número mínimo de estados de control en cada ruta. El algoritmo combina de manera óptima los horarios de ruta en un horario del sistema.
El horario para cada ruta se encuentra con camarilla que comprenda al menos, este paso se le conoce por el nombre como rápido-como-posible (AFAP) de programación.
Estimación del acelerador
Estimar los costos de hardware del acelerador de forma heterogénea multiprocesador, requiere una precisión de equilibrio y la eficiencia. Las estimaciones deben ser lo suficientemente buenas para evitar desorientar el proceso de síntesis global.
Sin embargo, las estimaciones se debe generar la suficiente rapidez que los compañeros de síntesis se puede explorar un gran número de diseños candidato. Métodos de estimación para la co-síntesis general, evitar estimaciones muy detallada de las características físicas, como podrían ser generados por la colocación y el enrutamiento. En su lugar, confían en la programación y asignación de medir el tiempo de ejecución y el tamaño del hardware.
Hermann et al.[Her94] utiliza métodos numéricos para estimar los costos del acelerador en COSYMA. Señalaron que como capas adicionales de un nido de bucle, se pelan para su aplicación en el acelerador, el costo de la modificación del acelerador no es igual a la suma del costo de las piezas nuevas y adicionales.
Por ejemplo, si una función se describe en tres bloques, a continuación, ocho términos que sean necesarias para describir el costo del acelerador que implemente los tres bloques.Utilizaron técnicas numéricas para estimar los costos del acelerador como elementos nuevos fueron agregados al acelerador.
Henkel y Ernst [Hen95; Hen01] desarrollaron un algoritmo para calcular de forma rápida y con precisión el funcionamiento del acelerador, y el costo dado un CDFG. Que utilizan la programación basada en rutas para calcular la longitud de la programación y los recursos necesarios para ser asignados.
Para reducir el tiempo de ejecución de las AFAP, y la superposición de medidas de planificación basada en rutas, que se descomponen los CDFG, y el horario de cada subgrafo de forma independiente, esta técnica es conocida como la ruta basada en la estimación. Ellos utilizar tres reglas para guiar la selección de los puntos de corte.
En primer lugar
Corte en los nodos con un número de iteraciones menor, ya que cualquier penalidad incurrida por el corte de la gráfica se multiplicará por el número de tritones.
En segundo lugar
Corte en los nodos donde se encuentran senderos al unirse, por lo general generados por el final de un ámbito en el lenguaje.
En tercer lugar
Tratar de cortar el gráfico en trozos más o menos del mismo tamaño. El número total de los trozos es posible que puede ser controlado por el diseñador.
Su algoritmo de estimación, incluida la creación de perfiles, lo que genera, y la conversión del CDFG, cortar el CDFG, y la superposición de los horarios se muestra en la Figura 7-4 a continuación.
Vahid y Gajski [Vah95] desarrollaron un algoritmo para la estimación rápida incremental de la ruta de datos y los costos de control. Que modelo de costos de hardware como una suma
C H = k FU S FU + k SU S SU + k M S M + k SR S SR + k C S C = k W S W (EQ 02/07)
donde S x es el tamaño de un determinado tipo de elemento de hardware y k x es la proporción de tamaño-costo de ese tipo. En esta fórmula, FU es función de las unidades. SU son las unidades de almacenamiento. M es multiplexores. SR se registra el estado. C es la lógica de control. W es el cableado.

Figura 4.7 Un algoritmo para la ruta basada en la estimación.
Se calcula a partir de estos parámetros más directos, tales como el número de estados en el controlador, las fuentes de los operandos de las operaciones, y así sucesivamente. Vahid y Gajski preprocesar el diseño para calcular una variedad de información para cada procedimiento en el programa.
1) Un conjunto de entradas de ruta de datos y un conjunto de salidas de ruta de datos.
2) El conjunto de funciones y unidades de almacenamiento.Cada unidad se describe por su tamaño y el número de líneas de control que acepta.
3) Un conjunto de objetos funcionales se describe por el número de estados posibles de control para el objeto y los destinos a los que el objeto puede escribir. Cada destino es descrito a sí mismo con un identificador, el número de estados en los que el destino está activo para este objeto, y las fuentes que el objeto se puede asignar a este destino.

Figura 7-5 Información preprocesado utilizado para la estimación de costos.
Una forma de tabla de esta información se muestra en la Figura 7-5 arriba. Esta información puede ser usada para calcular algunos valores intermedios como se muestra en la Figura 7-6 a continuación. Estos valores, a su vez puede ser utilizado para determinar los parámetros en ( EQ 07/02) .
Vahid y Gajski utilizar un algoritmo de actualización dado un cambio en la configuración de hardware. Dado un objeto de diseño, lo primero hay agregar el objeto al diseño, si todavía no existe. A continuación, actualizar las fuentes de multiplexor y tamaños y actualización de estados de la línea de control activo para este destino.

Figura 7-6 Representación tabular de los recursos de hardware.( Para ver la imagen grande, haga click aquí )
{kind=link}
Por último, actualizar el número de estados del controlador. Su algoritmo de actualización se ejecuta en tiempo constante si el número de destinos por objeto es aproximadamente constante.
Siguiente en la parte 2: Hardware / software de síntesis de co-algoritmos
Esta serie de dos artículos se basa en el material impreso con el permiso de Morgan Kaufmann, una división de Elsevier, Copyright 2007 de "computación de alto rendimiento integrado "por Wayne Wolf. Para obtener más información acerca de este título y otros libros similares, por favor visite www.elsevierdirect.com .
Wayne Lobo es actualmente el Georgia Research Scholar Alianza Eminentes la celebración de la Resa "Ray" S. Farmer, Jr., Presidente Distinguido de sistemas informáticos integrados en la Escuela de Tecnología de Georgia de Ingeniería Eléctrica y Computación (ECE).Anteriormente, un profesor de ingeniería eléctrica en la Universidad de Princeton, trabajó en AT & T Bell Laboratories.Se ha desempeñado como editor en jefe de las transacciones de ACM en Embedded Computing y de automatización de diseño para sistemas embebidos .
Vía:
No hay comentarios:
Publicar un comentario